In part one: Building a future-ready data platform, I looked at how choosing the right technology sets the foundation for a flexible and future-proof data platform. How important it is to start simple, avoid vendor lock-in and align your technology choices with your organisation’s maturity and use cases. These considerations mean that your platform evolves with your needs rather than becoming an expensive, static solution. If you haven’t read part one yet, I’d recommend starting there. You’ll also find deeper insights into balancing technology, culture, and use cases in our whitepaper Laying the groundwork for AI.
10 essential considerations for a flexible data platform
A future-ready data platform needs more than just the right technology. Every decision – how you ingest, store, process, and manage data – should prioritise flexibility.
A rigid platform will slow you down, while a well-designed one will allow you to adapt to changing requirements with minimal disruption.
Here are the 10 key factors to focus on when designing a future-proof data platform:
- Ingestion: Define the principles for pulling data into your platform in a way that reduces dependency on specific systems. Loose coupling means the platform will be able to adapt to evolving data sources. Assigning clear ownership will create accountability and predictability when exchanging data. How will your pipelines scale to handle both current and future data volumes?
- Storage: The design of your data storage should accommodate change with minimal disruption. Go for modular solutions that allow you to adjust the format, schema, or location of data without rewriting your entire platform. Use partitioning and naming conventions to simplify upgrades, cut costs and speed up retrieval.
- Computation and transformation: Data transformations should be built on reusable, well-documented functions that rely on standardised domain language. Idempotent transformation patterns – where the same inputs always yield the same outputs – help with consistency and reliability. This approach means that as your platform evolves, new transformations can integrate seamlessly without breaking existing processes.
- Workflow orchestration: Flexibility in triggering and linking transformation jobs is going to be key when the goalposts inevitably move. Choose tools and patterns that support dynamic scheduling and can allow workflows to scale or reconfigure as requirements change.
- Quality Assurance: Introduce robust methods for testing and maintaining data quality as it flows through the platform. As data volumes grow or new sources are added, continuous monitoring and anomaly detection will allow you to catch and resolve issues early.
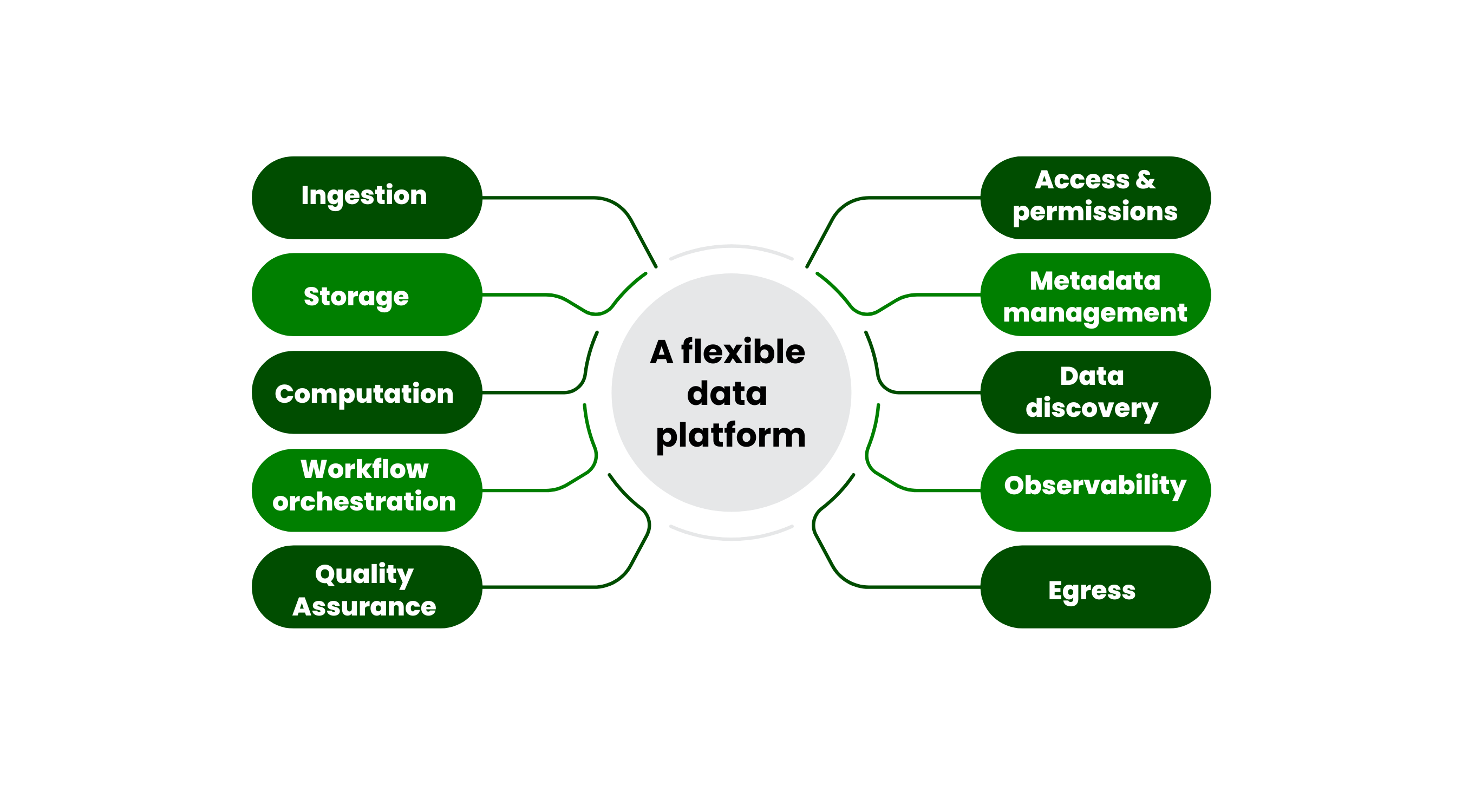
- Access and permissions: Prioritise security and efficiency. Define user roles, audit trails, and data handling to stay compliant while keeping onboarding flexible for new teams and partners.
- Metadata management: Data about your data plays a pivotal role in discovery and management. One way we address this is through data contracts. These aren’t legal agreements but rather encapsulations of all relevant metadata: schemas, usage rights, sharing policies, ownership and more. When co-published with data, contracts streamline cataloging and discovery. This makes it easier for teams to find and use what they need, as well as adapt to changing requirements.
- Data discovery: A platform is only as useful as its discoverability. Build tools and processes that help your users easily find, understand and use the available data. Make sure that your discovery mechanisms can scale to match your datasets.
- Observability: Observability is critical for understanding how your platform operates. When something fails (and it will), you need to pinpoint where and why it failed, assess the impact, and re-run processes where necessary. This is where tools like lineage tracking and telemetry come into play, helping teams stay on top of system health.
- Egress: Prioritise modularity when it comes to your design. Whether data flows into visualisation tools, operational systems, or external APIs, make sure that your egress mechanisms are scalable and adaptable to new business needs.
By designing your platform with flexibility in mind, you can avoid over-engineering. The result will be a platform that remains responsive to your future needs.
But having a flexible tech stack is just one piece of the puzzle. To truly future-proof your data platform, you also need the right governance, security, and operational practices to keep it efficient and adaptable. In my upcoming part 3, you’ll be able to find out how borrowing from DevOps principles can help you maintain a scalable, secure, and well-managed platform – without adding unnecessary complexity.
Whilst you’re waiting for part 3, take a look at our data and AI pages to find out more about the help we can provide in this space.
About the Author
Jim Stamp
Head of Technology at Made Tech
Jim has over two decades of experience working in and around software development, spanning many disciplines. He has led the way in establishing Made Tech’s data capability while also leading several major data platform projects.


